10 Strategies for Optimizing....
In the ever-evolving..
By Admin / 13 February

Most Node.js applications perform well in the beginning. Traffic stays controlled. APIs respond quickly. Deployments feel smooth, and small teams usually manage operations without much pressure. For a while, everything seems stable enough to continue growing comfortably. Then usage starts increasing.
More users arrive. Background jobs expand. Databases handle larger request volumes. Suddenly, the same application that once felt lightweight starts showing random delays. Response times fluctuate during busy hours. Memory consumption rises quietly. At times, servers begin struggling without throwing obvious errors.
And honestly, this is where many businesses realize performance problems rarely appear overnight. They build gradually through small inefficiencies that stay unnoticed during early growth stages.
That is one reason development teams now pay closer attention to vps web hosting before scaling production environments aggressively. Because even a well-built Node.js application eventually slows down if the infrastructure underneath cannot support consistent workload distribution properly.
Node.js became popular because of its asynchronous architecture. It handles concurrent operations efficiently and works especially well for real-time applications.
However, production traffic changes everything.
An application that performs smoothly with hundreds of users may behave very differently once thousands of requests begin arriving continuously. Small delays suddenly become visible because every operation starts competing for server resources simultaneously.
Sometimes the slowdown comes from:
Other times, the application logic works perfectly while the server environment itself struggles to distribute resources efficiently.
And this is exactly why optimization cannot focus only on development.
Stable production systems usually depend on balance between:
Without that balance, applications slowly become harder to scale reliably.
This is one of the most frustrating production issues for growing applications.
Initially, everything appears normal. The server remains active, requests continue processing, and uptime looks stable from the outside. Meanwhile, memory usage quietly keeps increasing in the background.
Then the symptoms start appearing gradually.
Applications begin restarting unexpectedly. CPU usage spikes during normal traffic. Response times become inconsistent. Eventually, teams start troubleshooting random slowdowns without immediately understanding where the instability actually started.
In many situations, the problem connects back to:
These issues often stay hidden during development because local environments rarely simulate real production pressure accurately.
Consequently, production traffic exposes weak memory management much faster than internal testing usually does.
A powerful application running on unstable infrastructure eventually reaches limitations.
And surprisingly, many businesses underestimate this part until scaling problems become visible publicly.
Production Node.js environments need systems capable of handling:
without creating operational bottlenecks during traffic surges.
This is where properly configured vps hosting environments become extremely useful because developers gain stronger control over:
Shared environments may feel sufficient initially, although they often become unpredictable once applications begin handling heavier workloads consistently.
Meanwhile, isolated server environments generally create smoother operational behavior during growth periods.
One failed process should never bring down the entire application.
Still, smaller production environments often continue running without proper process management until downtime becomes impossible to ignore.
Reliable process managers help teams:
As a result, applications remain more stable even when traffic pressure increases unexpectedly.
And honestly, users notice instability much faster than businesses expect. A few slow responses may feel minor internally, but repeated interruptions quickly damage user confidence.
When applications slow down, developers often investigate APIs first.
Meanwhile, database queries frequently create the real bottleneck underneath.
A poorly optimized query repeated thousands of times can gradually affect:
especially in applications handling:
That is why optimization usually requires reviewing:
because performance issues rarely come from a single source alone.
More often, multiple smaller inefficiencies combine until the application begins feeling unstable during normal usage.
Not every request requires fresh computation.
Still, many applications repeatedly process identical operations for information that barely changes within short intervals. Over time, that behavior creates unnecessary pressure across the entire infrastructure stack.
Good caching strategies help reduce:
while improving response consistency simultaneously.
And interestingly, even small caching improvements often create noticeable speed gains surprisingly quickly.
Especially during high-traffic periods where repeated operations become heavier.
Detailed logs feel helpful during debugging.
However, excessive logging inside production environments slowly affects system efficiency if teams do not manage it carefully.
Large logging operations can:
particularly under continuous traffic conditions.
Strong production systems therefore focus on intelligent logging instead of recording every small activity unnecessarily.
The goal is operational visibility without adding extra pressure to the application itself.
Applications rarely fail because traffic suddenly explodes in one moment.
Most production instability builds gradually while infrastructure remains unchanged underneath growing demand.
That is exactly why performance optimization should happen before users begin noticing visible slowdowns publicly.
Businesses investing early in dependable server environments usually focus heavily on:
because reactive optimization becomes far more difficult once customer experience starts suffering directly.
And honestly, rebuilding user trust after repeated downtime usually costs more than strengthening infrastructure earlier.
Node.js applications can scale extremely well, but long-term production stability depends on much more than fast code alone. As traffic increases, even smaller inefficiencies inside memory handling, database communication, caching, or process management start affecting application behavior more noticeably. Gradually, systems that once felt lightweight begin struggling under operational pressure if optimization never evolves alongside growth.
That is why modern production environments require stronger planning before scaling aggressively. Businesses now focus more carefully on server stability, resource control, workload balancing, and monitoring because performance problems rarely stay limited to technical inconvenience alone. Teams that invest early in dependable hosting services usually maintain smoother application performance, stronger uptime consistency, and far fewer operational disruptions as their platforms continue expanding.

In the ever-evolving..
By Admin / 13 February

In the frantic world..
By Admin / 19 January

Technology is the..
By Admin / 27 December

WordPress, standing as..
By Admin / 27 November

In the ever-evolving..
By Admin / 18 October

Businesses struggle..
By Admin / 30 September

Web hosting is the..
By Admin / 21 September

Your website's speed and..
By Admin / 12 September

For every organization..
By Admin / August 23

For every organization..
By Admin / August 8

In the modern digital..
By Admin / July 21

As we are living..
By Admin / July 7

Dedicated hostings are..
By Admin / June 29

When you look into the..
By Admin / June 15

Dedicated servers are..
By Admin / May 18

Unmanaged VPS hosting..
By Admin / May 13

There has been..
By Admin / May 02

As soon it comes to..
By Admin / April 12

The hosting environment..
By Admin / Mar 25
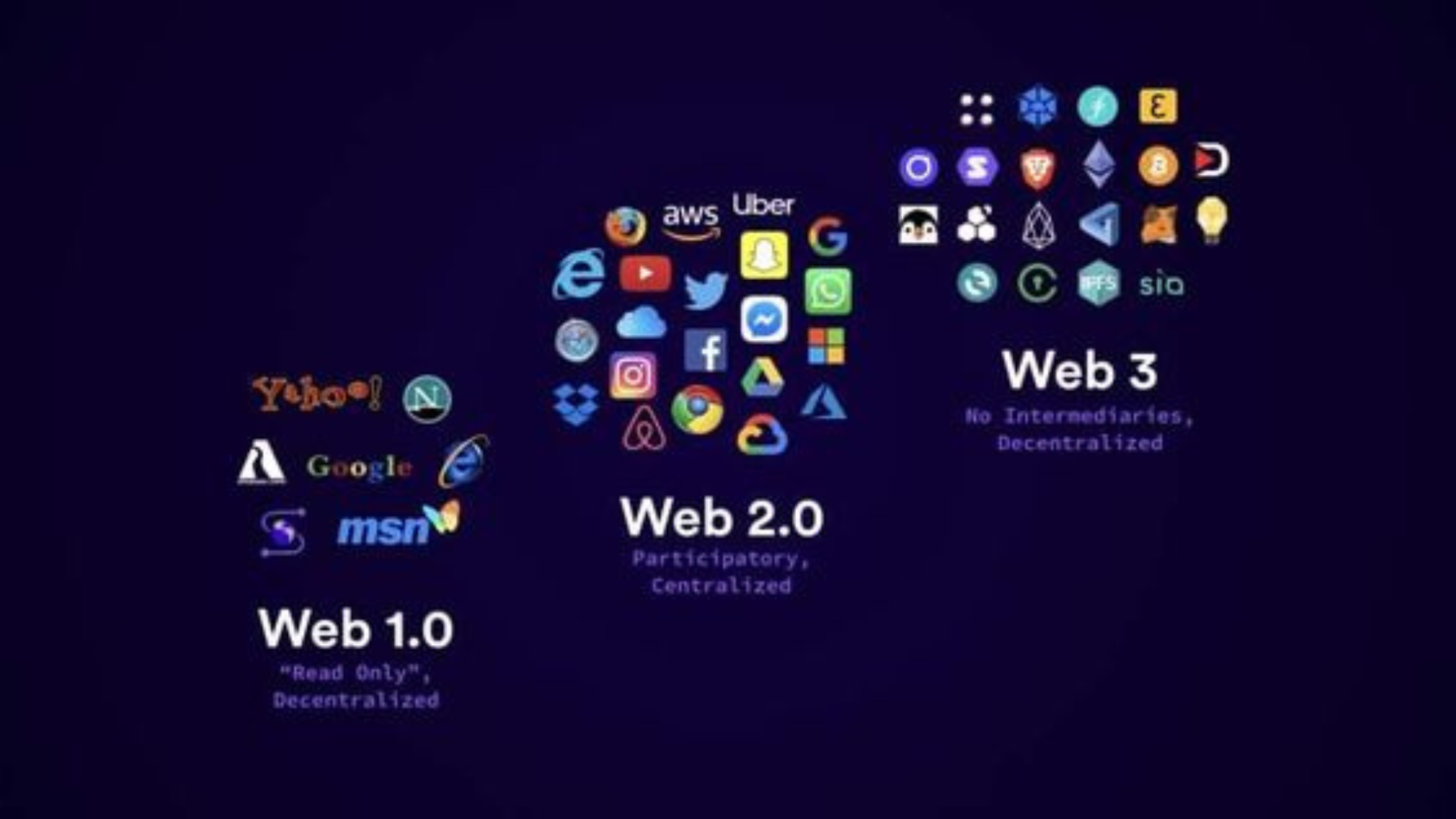
The internet has undergone..
By Admin / Mar 14
Whenever we talk..
By Admin / Mar 13

As we all know..
By Admin / Feb 28

Web server hosting is a..
By Admin / Feb 13
Web server hosting business
By Admin / Feb 13
Your website running slow?
By Admin / Feb 05

Introducing quizzes
By Admin / May 12

If you are a beginner in...
By Admin / May 20




{kind=link}